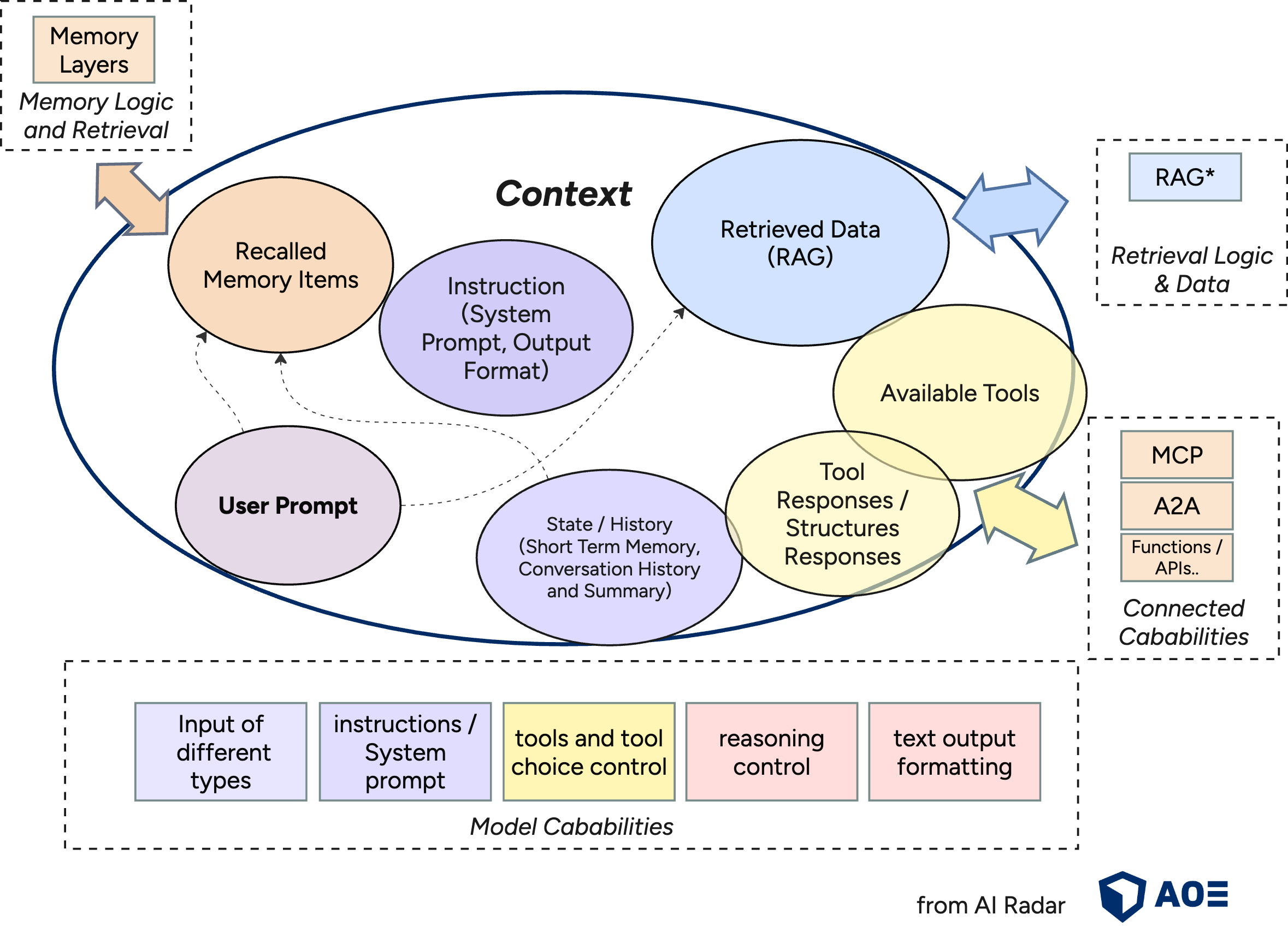
Context Engineering is the discipline of designing and building dynamic systems that provides the right information and tools, in the right format, at the right time, to give a LLM everything it needs to accomplish a task.
As Large Language Models (LLMs) become core components in AI applications context engineering has emerged as a critical architectural concern. The term refers to the design of the input context passed to LLMs - including - data, prompts, state, tools, memory etc. How they are selected, formatted, and ordered, to ensure robustness, reproducibility, and quality of the LLM output is a very important concern.
Prompt engineering and context engineering are somewhat overlapping concepts, but while Prompt engineering focuses on crafting effective instructions within the prompt, context engineering puts focus on the broader design of the entire input—including prompts, retrieved data, current conversation history, memory, tools and tool outputs.
Motivation
LLMs process information within a sequential context window (e.g., 4k to 200k tokens). The quality and relevance of the generated output depend heavily on what information is included in the context and how it is structured and prioritized. In production-grade agentic systems or RAG pipelines, effective context engineering is often the difference between brittle prototypes and scalable solutions.
Additionally the models and theire APIs provide different cababilities for structured requests, that should be used to optimize results. For example the openAI API provides request parameters to specify provided tools and theire usage instructions.
Techniques in Context Engineering
It is Dynamic, not a string: The context is the output of a system that runs before tcalling the model. It is created on the fly, tailored to the task.
RAG Optimization: In retrieval-augmented systems, context engineering starts with effective retrieval strategies. See Advanced & Modular RAG and Graph RAG for deeper dives into these approaches.
Window Management and Memory: When interactions span long sessions (e.g., with agents), token budget becomes a key constraint. Techniques for managing long-term context include: sliding window approaches, context pruning, and summarization.
Memory for more context: Some use cases require access to previous conversations or results. See mem0: memory-optimized agent framework mom0 for an example of advanced memory in practice.
Test variation and measure impact: Maintain evaluation sets to test and tune prompt and context effectiveness. Tools like Ragas and DeepEval provide practical frameworks for evaluating and benchmarking LLM outputs.
format matters: How you present information matters. A concise summary is better than a raw data dump. A clear tool schema is better than a vague instruction.
Proper Tool Design: Supplying the LLM with well-designed tools and clear tool descriptions is as crucial as providing relevant information. Tool outputs and error responses should be descriptive and optimized for the model context. Also avoid adding tools dynamic during a "conversation". For a deeper dive, see MCP protocol.
Own your prompt and own your context: Don't "outsource" your prompt to framework black boxes. own your prompts and treat them as first-class code. Use templates if useful.
Optimize for Cache: Models have a KV-Cache, that helps AI models generate text faster and more efficiently. By putting new context information at the end you help using this cache.
Further Resources
- The Rise of Context Engineering (LangChain Blog)
- Context Engineering by Phil Schmid (Google Deepmind)
- Kontext-Engineering für KI-Agenten: Lektionen aus dem Aufbau von Manus