Ragas
evaluationRagas is a framework for evaluating and monitoring Retrieval Augmented Generation (RAG) applications. It provides comprehensive metrics and tools to assess the quality, reliability, and performance of AI systems that combine language models with external knowledge bases.
The alternative Deepeval is integrated in an ecosystem and to our experience is more user-friendly for most use cases.
Key Features
- Automated evaluation of RAG pipelines with industry-standard metrics
- Built-in support for popular vector databases and embedding models
- Comprehensive scoring for context relevance, answer faithfulness, and retrieval quality
- Integration with major LLM platforms and frameworks
- Detailed analytics and visualization capabilities
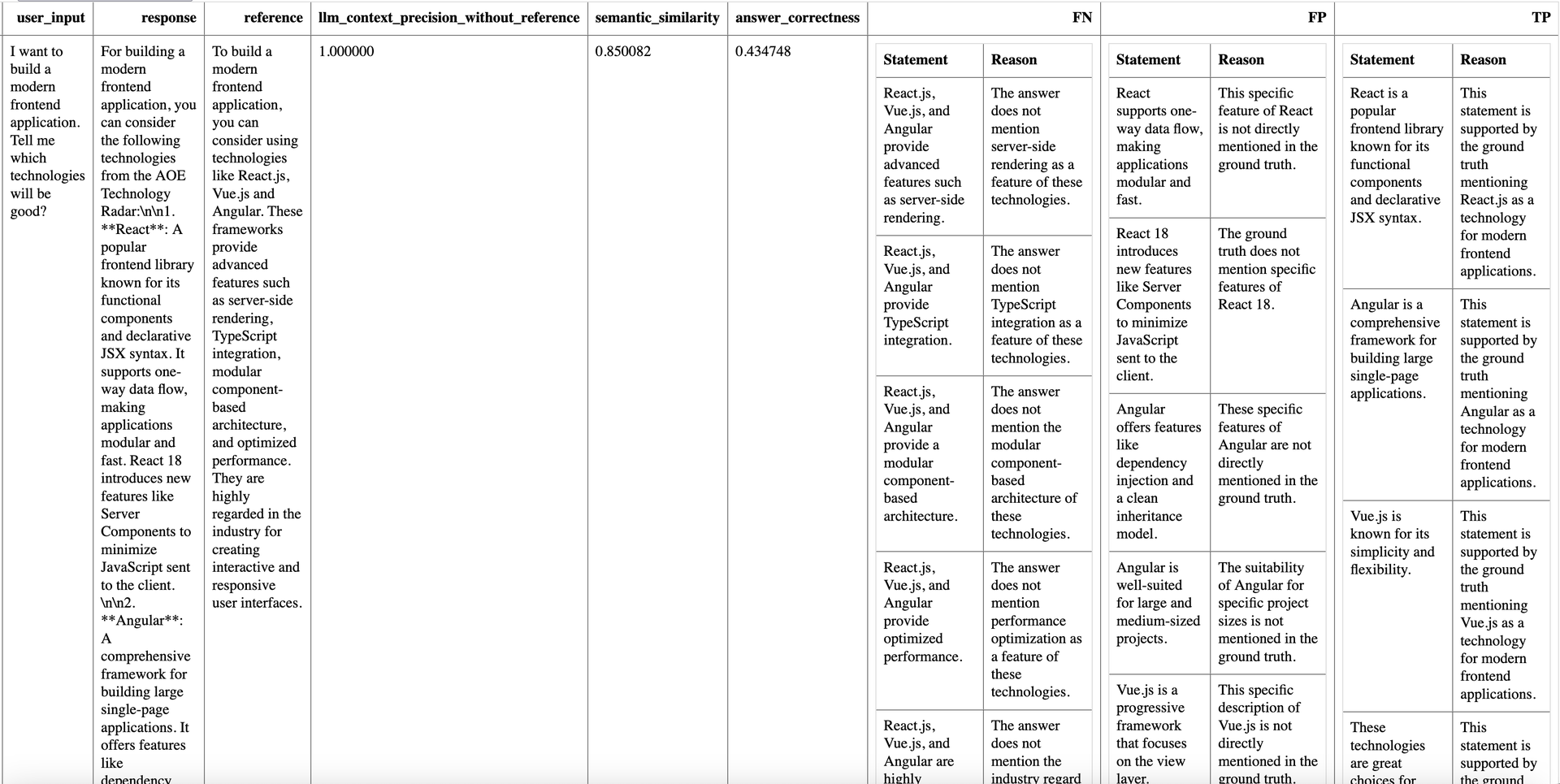 Example: Ragas output showing evaluation metrics, semantic similarity, and answer correctness for a sample RAG pipeline.
Example: Ragas output showing evaluation metrics, semantic similarity, and answer correctness for a sample RAG pipeline.
Business Value
- Improve accuracy and reliability of AI applications
- Reduce hallucinations and incorrect responses
- Optimize retrieval strategies and knowledge base quality
- Monitor production RAG systems in real-time
- Make data-driven decisions about model and retrieval improvements
Use Cases
- Evaluating the quality of RAG pipelines
- Research scenarios requiring custom or experimental metrics
- Projects where legacy Ragas integration already exists
Integration
- Requires manual configuration for most metrics and workflows
- Integrates with LangChain and other Python LLM frameworks
- Output can be exported for further analysis
Team Insights
Our team has encountered several significant challenges while working with Ragas:
- Documentation and Support:
- Documentation contains significant gaps and errors
- Steep learning curve for new team members
- Certain important features like Persona and custom prompts are not well higlighted
- Lack of clear versioning and backward compatibility
- Technical Challenges:
- Complex setup required for both local development and CI/CD pipeline integration
- Upgrading to newer versions broke the setup on certain occasions
- No built-in visualization tools for evaluation results analysis
- Evaluation Reliability:
- Evaluations often lack transparency in decision-making
- No clear explanation of how the tool reaches conclusions
- Results can be inconsistent across different runs
- Integration Issues:
- Extra overhead to implement reporting for CI/CD runs
- Requires extensive manual configuration
Recommendation
For most evaluation scenarios, especially those focused on RAG or basic LLM output quality, we recommend using Deepeval. Ragas may be considered if you need very specific custom metrics or are already invested in its ecosystem, but be prepared for additional configuration effort and documentation issues.
Related Topics
- Official Documentation
- GitHub Repository
- RAG
- Model Leaderboards
- Deepeval (recommended alternative)